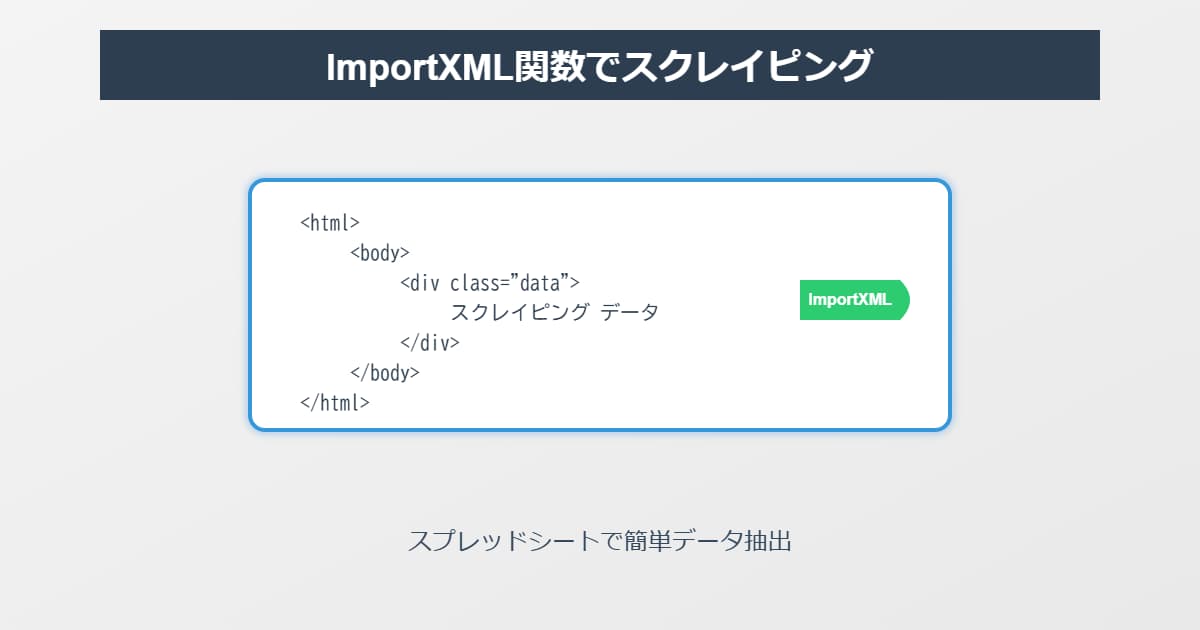
importxml関数を使ってスプレッドシートでスクレイピングする方法を解説します。
IMPORTXML関数とは?
XML、HTML、CSV、TSV、RSS フィード、Atom XML フィードなど、さまざまな種類の構造化データからデータをインポートします。
使用例
IMPORTXML(“https://en.wikipedia.org/wiki/Moon_landing”, “//a/@href”)IMPORTXML(A2,B2)
importxmlの「xml」とは?
importxmlの「xml」は、文章の見た目や構造を記述するためのマークアップ言語のことです。
importxmlの使い方
タイトルの抽出
=IMPORTXML(A1,"//title")見出しの抽出
=importxml(A1,"//h1")=importxml(A1,"//h2")=importxml(A1,"//h3")=importxml(A1,"//h4")=importxml(A1,"//h5")メタディスクリプションの抽出
=IMPORTXML(A1,"//meta[@name='description']/@content")og:titleの抽出
=IMPORTXML(A1,"//meta[@property='og:title']/@content")og:descriptionの抽出
=IMPORTXML(A1,"//meta[@property='og:description']/@content")meta og:typeの抽出
=IMPORTXML(A1,"//meta[@property='og:type']/@content")meta og:urlの抽出
=IMPORTXML(A1,"//meta[@property='og:url']/@content")meta og:imageの抽出
=IMPORTXML(A1,"//meta[@property='og:image']/@content")meta og:site_nameの抽出
=IMPORTXML(A1,"//meta[@property='og:site_name']/@content")canonical URLの抽出
=IMPORTXML(A1,"//link[@rel='canonical']/@href")meta keywordsの抽出
=IMPORTXML(A1,"//meta[@name='keywords']/@content")Hreflang attributesの抽出
=Hreflang attributes: "//link[@rel='alternate']/@hreflang"Robotsの抽出
=IMPORTXML(A1,"//meta[@name='robots']/@content")

コメント